

Exemplo de ELS, domínio público via Wikimedia Commons
Em 1994, a revista acadêmica Statistical Science publicou um artigo afirmando que nomes de rabinos famosos, com datas de nascimento e morte, apareciam escondidos no texto hebraico de Gênesis — uma letra a cada N posições, num padrão chamado Equidistant Letter Sequence (ELS). Cinco anos depois, a mesma revista publicou a refutação. O editor escreveu que, considerado o conjunto do trabalho dos críticos, “fica claro que o quebra-cabeça foi resolvido”. Não a favor do código.
Esse é um dos três jogos de números que costumam se misturar quando o assunto é “matemática escondida na Bíblia”. O método de Haim Shore, que abrimos no post anterior desta série, é um terceiro jogo, estruturalmente diferente dos outros dois. Vale separar os três antes de seguir.
A Bíblia em código (ELS)
A técnica é simples de descrever. Escolhe-se um ponto de partida no texto e um “número de salto”: lendo cada N-ésima letra a partir dali, surgem palavras escondidas. A imagem deste post mostra o exemplo clássico, extraído de Gênesis 26.5-10 na King James Version: pulando de quatro em quatro letras, aparecem “Bible” e “code” cruzando o texto em diagonal.
A ideia não nasceu em 1994. Comentaristas judeus já descreviam sequências assim séculos antes. O que mudou foi o computador, que permitiu testar a hipótese em escala. Doron Witztum, Eliyahu Rips e Yoav Rosenberg rodaram o chamado “experimento dos grandes rabinos”: testaram se os nomes de rabinos famosos apareciam, via ELS, próximos demais de suas respectivas datas de nascimento e morte para ser acaso. O resultado foi publicado como “Equidistant Letter Sequences in the Book of Genesis”, na Statistical Science1 — mas o próprio corpo editorial da revista, desconfiado, decidiu publicá-lo como um “quebra-cabeça desafiador” para a comunidade estatística resolver, não como um achado validado.
Quem resolveu foi outro grupo. Brendan McKay, Dror Bar-Natan, Maya Bar-Hillel e Gil Kalai publicaram, na mesma revista, em 1999, “Solving the Bible Code Puzzle”.2 A conclusão: o experimento original era “fatalmente defeituoso”, e o resultado refletia escolhas feitas no desenho do experimento — qual grafia de cada nome usar, qual data considerar — não um padrão real no texto. Para provar o ponto, reproduziram um efeito parecido na tradução hebraica de Guerra e Paz, de Tolstói. O editor da revista, Robert Kass, que cinco anos antes chamara o artigo original de “quebra-cabeça desafiador”, escreveu na introdução à réplica que “considerado o conjunto do trabalho de McKay, Bar-Natan, Kalai e Bar-Hillel, fica claro, como eles concluem, que o quebra-cabeça foi resolvido”.
O jornalista Michael Drosnin popularizou a ideia fora do círculo acadêmico com o best-seller The Bible Code (1997) — e foi além do que os próprios autores do experimento sustentavam. Eliyahu Rips chegou a emitir uma declaração pública se distanciando das conclusões de Drosnin. As previsões do livro também não se confirmaram: Drosnin anunciou em Bible Code II (2002) um “holocausto atômico” mundial que nunca ocorreu, armas de destruição em massa líbias entregues a terroristas — a Líbia entregou seu programa de armas em 2003, não o expandiu — e o assassinato de Yasser Arafat por pistoleiros do Hamas. Arafat morreu em 2004, de causas naturais.
O matemático e ganhador do Nobel de Economia Robert Aumann acompanhou a controvérsia por anos antes de concluir: “a priori, a tese da pesquisa dos Códigos parece extremamente improvável3 (…) por isso devo retornar à minha estimativa a priori, de que o fenômeno dos Códigos é improvável”.
A numerologia de Ivan Panin
Ivan Panin nasceu na Rússia em 1855, foi exilado aos 18 anos por atividade revolucionária, emigrou e se formou em Harvard. Era um agnóstico declarado. Sua conversão ao cristianismo, em 1890, começou com um detalhe gramatical: no grego de João 1.1, o artigo “o” aparece antes de “Deus” numa cláusula e não na seguinte. Panin passou a investigar se havia um padrão matemático por trás dessas escolhas — e dedicou os 50 anos seguintes, e mais de 43 mil páginas manuscritas, a procurar múltiplos de sete no grego do Novo Testamento e no hebraico do Antigo.
O exemplo mais citado é Gênesis 1.1: Gênesis 1.1 tem, no hebraico, sete palavras e 28 letras — 28 = 4 × 7.4 Panin encontrou dezenas de padrões parecidos e os tratou como prova de inspiração divina verbal.
Há um problema estrutural nesse método que não existe nos outros dois. Panin não estava satisfeito com o texto grego recebido (a edição de Westcott e Hort, a referência da época): produziu sua própria edição crítica do Novo Testamento grego, em 1934, escolhendo entre variantes manuscritas a leitura que melhor se encaixava nos padrões de sete que ele já esperava encontrar. Críticos — entre eles o mesmo Brendan McKay que ajudou a derrubar o código bíblico — apontam o problema óbvio: um método que constrói o próprio texto para caber no padrão não pode depois alegar o padrão como prova. É raciocínio circular.
Onde o método de Shore é outra coisa
ELS busca padrões escondidos dentro do texto. A numerologia de Panin também — e, no caso dele, dentro de um texto que ele próprio ajustou. O método de Shore faz algo diferente: pega um pequeno conjunto de palavras hebraicas — três, ou nove — cujo significado não é disputado, e testa se o valor numérico de cada uma se alinha, numa reta de regressão, com uma medida física da mesma palavra obtida fora do texto, em fontes como a NASA ou tabelas de engenharia.
Um exemplo do artigo de Shore: as palavras para dia, mês e ano (yom, yerach, shanah) somam, respectivamente, 56, 218 e 355. Convertendo a duração de cada período em frequência (ciclos por segundo) — usando dados astronômicos, não o texto —, os três pontos se alinham numa reta com correlação de -0,9992, com significância de 2,5%. Outro exemplo: as palavras para gelo, água e vapor (kerach, mayim, kitor) somam 308, 90 e 325; o calor específico de cada fase da água, medido em laboratório, se alinha a esses valores com correlação de -0,9995 (p<0,021).5
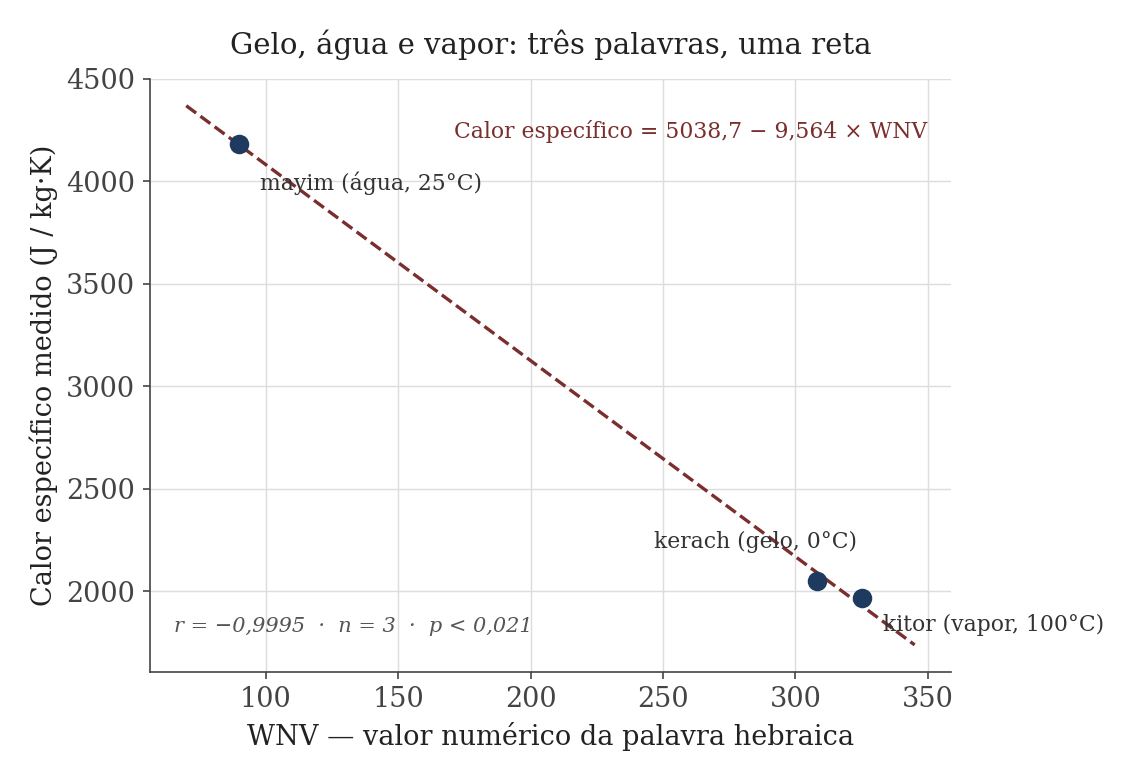
Gráfico: elaborado pelo autor, com dados de Haim Shore (2011) e do Engineering ToolBox.
Três fases da mesma substância, três palavras hebraicas, uma reta com r=-0,9995. É o tipo de ajuste que, em qualquer laboratório, levaria a uma segunda olhada — não a um descarte.
Para verificar se três pontos alinhados são apenas sorte, Shore rodou uma simulação: gerou por computador dez mil trios de palavras hebraicas aleatórias (respeitando a frequência real das letras na Bíblia) e mediu quantos desses trios aleatórios produziriam um alinhamento tão bom quanto o observado para luz, som e silêncio. A resposta: menos de 1%. É um teste de chance verificável — e diferente, num ponto que importa, do ponto fraco do código bíblico, porque aqui não há “número de salto” ou grafia alternativa para ajustar até achar um encaixe. As palavras e as medidas físicas estão fixadas antes do teste.
O exemplo mais robusto do método inteiro — nove pontos, não três — fica para mais adiante nesta série: os nove “planetas” da Bíblia. Adianto um número: a correlação entre o valor numérico das palavras e o diâmetro real dos planetas chega a r=0,98, com probabilidade de ocorrência por acaso menor que duas em um milhão (p<0,000002). É o tipo de resultado que, em qualquer outro campo, pediria uma reanálise séria — não uma rejeição automática. Vamos abrir essa tabela com calma.
O que o próprio Shore admite que pode falhar
Shore dedica uma seção do seu artigo a se antecipar às críticas, e não foge da mais incômoda: a de que está escolhendo a dedo (“cherry picking”) os exemplos que funcionam e ignorando os que não funcionam. Ele não nega a objeção — diz que ela é “séria e não pode ser descartada” — e responde apontando para a amostra de nove pontos dos planetas como o tipo de evidência cumulativa necessária para superá-la. Conclui, com uma honestidade rara no gênero: “acreditamos que esse limiar foi superado. Outros podem discordar.”
Ele também reconhece que nem toda palavra hebraica “se encaixa” nesse padrão — só entram na amostra palavras sem sinônimo e sem ambiguidade de sentido, o que limita o universo de testes possíveis. No exemplo das cores, por exemplo, apenas quatro das sete cores primárias aparecem na Bíblia; ordenadas pelo valor numérico, coincidem com a ordem de suas frequências de onda — uma chance de 1 em 120 de ocorrer ao acaso.
Isso não resolve a questão. Mas distingue os três campos: o código bíblico foi testado e refutado pela mesma comunidade estatística que primeiro o publicou. A numerologia de Panin nunca passou por um teste equivalente, porque seu método depende de um texto que ele mesmo ajustou. O método de Shore não foi revisado por pares — isso já dissemos no post anterior —, mas lista as próprias objeções em vez de escondê-las. Isso não o torna automaticamente correto. Torna a conversa mais séria que a alternativa.
No próximo post, voltamos ao primeiro exemplo desta série — dia, mês, ano — e abrimos outros “relógios” do hebraico bíblico.
Referências
-
Witztum, Rips e Rosenberg. “Equidistant Letter Sequences in the Book of Genesis.” Statistical Science 9(3), 1994. ↩
-
McKay, Bar-Natan, Bar-Hillel e Kalai. “Solving the Bible Code Puzzle.” Statistical Science 14(2), 1999. ↩
-
“Bible code.” Wikipedia. ↩
-
“Ivan Panin.” Wikipedia. ↩
-
“Water - Specific Heat at Various Temperatures.” Engineering ToolBox. ↩
Tem algo a dizer sobre este texto? Manda uma mensagem — responderei em breve.




{kind=link}
{kind=link}